
Collection에서 "hash"라는 용어는 일반적으로 해시 기반 자료구조(Hash-based data structure)와 관련된 의미로 사용됩니다. 이러한 자료구조들은 객체를 저장하고 검색하기 위해 해시 함수(hash function)를 사용하여 객체를 해시 값으로 변환하고, 해당 해시 값을 인덱스로 사용하여 객체를 저장하거나 검색합니다.
해시(Hash)는 임의의 크기를 갖는 데이터[Key]를 고정된 크기의 값으로 변환하는 알고리즘입니다. 이렇게 변환된 값은 해시 값 또는 해시 코드라고도 합니다. 해시 함수는 입력 데이터의 작은 변화에도 결과 값이 크게 달라지도록 설계되어 있습니다. 따라서 입력 데이터가 달라지면 해시 값도 크게 달라집니다.
➡️ Key로 많이 사용되는 것은 다양한데, 일반적으로 다음과 같은 요소들이 키로 많이 활용됩니다.
- 숫자
숫자는 고유한 값을 가지고 있고, 비교적 간단하게 처리할 수 있으므로 키로 많이 사용됩니다. 예를 들어, 고객 ID, 주문 번호, 학번 등은 숫자로 된 키로 사용될 수 있습니다.
- 문자열
문자열도 키로 많이 사용됩니다. 예를 들어, 이메일 주소, 사용자명, 도메인 이름 등은 문자열로 된 키로 사용될 수 있습니다. 문자열은 다양한 길이와 형식을 가지고 있어 다양한 데이터를 식별하는 데에 유용합니다.
- UUID(Universally Unique Identifier)
UUID는 범용 고유 식별자로, 일반적으로 128비트 숫자로 표현됩니다. UUID는 충돌 가능성이 매우 낮아서 중복되지 않는 키로 사용하기에 좋습니다. 주로 분산 시스템에서 데이터 식별을 위해 사용됩니다.
- 해시 값
해시 함수를 사용하여 데이터를 해시 값으로 변환하고, 이를 키로 사용하는 경우도 많이 있습니다. 해시 값은 고유한 값을 가지며, 해시 함수의 특성에 따라 작은 변화에도 큰 차이를 보이므로 키로 적합합니다. 예를 들어, 파일의 체크섬이나 데이터의 무결성 검사를 위해 해시 값이 키로 사용될 수 있습니다.
- 조합된 키
여러 속성이나 값들을 조합하여 키로 사용하는 경우도 많습니다. 예를 들어, 이름과 생년월일을 조합하여 고유한 식별자를 생성하는 경우가 있습니다.
✅ 해쉬 함수(Hash function)

해시 함수(Hash function)는 임의의 길이의 데이터를 입력으로 받아 고정된 길이의 해시 코드(Hash code)를 반환하는 함수입니다. 해시 함수는 주어진 입력에 대해 동일한 해시 코드를 생성해야 하며, 입력이 조금만 변경되어도 완전히 다른 해시 코드를 생성해야 합니다. 입력 데이터의 작은 변화에도 결과 값이 크게 달라지도록 설계(일명 눈사태)되었습니다. 이러한 특성을 갖는 해시 함수는 다양한 컴퓨터 과학 및 정보 보안 분야에서 사용됩니다.
해시 함수는 입력 데이터의 작은 변화에도 결과 값이 크게 달라지도록 설계(일명 눈사태)되었으므로, 다음과 같은 의미가 있습니다
- 일부 데이터 변경의 전파 제한
입력 데이터의 작은 변화가 해시 함수의 결과에 큰 영향을 미치기 때문에, 해시 값의 작은 차이는 입력 데이터의 작은 차이에 대응합니다. 이러한 특성은 입력 데이터의 미세한 변경이 해시 값에 큰 영향을 미치는 것을 방지하며, 입력 데이터의 일부분만 변경되더라도 전체 해시 값이 크게 달라지는 현상을 발생시킵니다. 이는 데이터의 무결성 검사에 유용하며, 예를 들어 파일의 내용이 하나의 비트만 변경되더라도 해시 값이 완전히 다른 값으로 변하게 됩니다.
- 보안 및 무결성 검사
해시 함수의 결과 값이 작은 변화에도 크게 달라지도록 설계되면, 누구나 원본 데이터를 알지 못하더라도 동일한 입력에 대해 동일한 해시 값을 얻을 수 있습니다. 이 특성은 패스워드 저장, 메시지 인증 코드 등 보안 및 무결성 검사에 사용됩니다. 작은 입력 변경은 해시 값의 완전히 다른 값으로 변환되므로, 데이터의 위조나 변조를 감지할 수 있습니다.
- 해시 테이블의 성능 개선
해시 함수의 결과 값이 입력 데이터의 작은 차이에 큰 영향을 받으면, 해시 테이블과 같은 자료 구조에서 충돌을 최소화할 수 있습니다. 입력 데이터가 조금만 다른 경우에도 서로 다른 해시 값이 생성되므로, 해시 테이블의 성능이 향상됩니다. 이는 검색, 캐싱 등의 작업에서 유용합니다.
👉 결론적으로, 해시 함수가 입력 데이터의 작은 변화에 크게 반응하는 것은 데이터 무결성, 보안, 자료 구조의 성능 향상 등 다양한 응용 분야에서 유용한 특성을 가지게 됩니다.
해시 함수는 데이터를 해시 코드로 변환함으로써 데이터를 고유하게 식별하고, 데이터의 검색과 비교를 빠르게 수행할 수 있습니다. 해시 함수는 데이터의 효율적인 저장, 검색, 정렬, 중복 제거, 데이터 무결성 확인, 암호화 등에 사용됩니다. 해시 함수의 결과물인 해시 코드는 일반적으로 정수 형태로 표현되며, 해시 테이블, 해시 집합, 해시 맵 등에서 사용되어 데이터의 접근과 관리를 용이하게 합니다.
➡️ 좋은 해시 함수는 다음과 같은 특징을 갖습니다:
- 일관성: 동일한 입력에 대해서는 항상 동일한 해시 코드를 반환해야 합니다.
- 고유성: 서로 다른 입력에 대해서는 가능한 한 충돌이 발생하지 않아야 합니다. 즉, 서로 다른 입력에 대해 동일한 해시 코드를 생성하는 충돌을 최소화해야 합니다.
- 고르게 분포: 입력 공간을 해시 코드 공간으로 고르게 매핑해야 합니다. 입력의 약간의 변화가 해시 코드에 큰 영향을 미치지 않아야 합니다.
- 계산 효율성: 해시 함수는 빠르게 계산되어야 합니다.
대표적인 해시 함수로는 MD5, SHA-1, SHA-256 등이 있으며, 각각 다양한 애플리케이션에서 사용됩니다. 또한, 자료구조에서 사용되는 해시 함수들은 특정 요구사항에 맞게 설계되어 성능을 최적화합니다.
✅ 해쉬 테이블(Hash Table)

해시 테이블(Hash Table)은 키(key)와 값(value)으로 이루어진 데이터를 저장하는 자료구조입니다. 해시 테이블은 해시 함수(hash function)를 사용하여 키를 해시 값으로 변환하고, 해당 해시 값을 인덱스로 사용하여 값을 저장하고 검색하는 방식으로 동작합니다.
해시 테이블은 배열로 구성되어 있으며, 각 배열 요소를 버킷(bucket)이라고 합니다. 각 버킷은 키와 값의 쌍을 저장하는 엔트리(entry)로 구성됩니다. 해시 함수는 키를 해시 값으로 변환하는 역할을 수행하며, 이 해시 값을 인덱스로 사용하여 해당 버킷에 엔트리를 저장하거나 검색합니다.
➡️ 해시 테이블(Hash table)은 다음과 같은 구성 요소로 구성됩니다.
- 해시 함수 (Hash function)
해시 함수는 입력 데이터를 해시 코드로 변환하는 알고리즘입니다. 입력 데이터의 특성에 따라 해시 함수는 고유한 해시 코드를 생성해야 합니다. 이 해시 코드는 버킷의 인덱스로 사용되어 데이터를 저장하고 검색할 수 있게 합니다.
- 버킷(bucket)
버킷은 해시 테이블에서 데이터를 저장하는 단위입니다. 각 버킷은 하나 이상의 엔트리(entry)를 저장할 수 있습니다. 엔트리는 키와 값의 쌍으로 구성되며, 키는 데이터를 식별하는 역할을 합니다. 키를 해시 함수를 통해 해시 값으로 변환하고, 해당 해시 값을 인덱스로 사용하여 해당 버킷에 엔트리를 저장하거나 검색합니다.
해시 테이블의 크기는 일반적으로 해시 값을 인덱스로 사용할 수 있는 배열의 크기로 결정됩니다. 예를 들어, 크기가 10인 해시 테이블은 10개의 버킷으로 구성된 배열을 의미합니다. 각 버킷은 개별 체이닝(Separate Chaining) 또는 개방 주소법(Open Addressing)의 일부로 구성될 수 있습니다. 연결 리스트 방식에서는 각 버킷이 데이터를 저장하는데 사용되며, 동일한 해시 값이 발생하는 경우 해당 버킷에 있는 연결 리스트에 데이터가 추가됩니다. 개방 주소법에서는 버킷 자체가 데이터를 저장하는데 사용되며, 충돌이 발생할 경우 다른 빈 버킷을 찾아 데이터를 저장합니다.
👉 버킷의 역할은 데이터를 해시 값에 따라 저장하고, 데이터의 검색을 위해 해당 버킷을 참조하는 것입니다. 해시 테이블은 버킷을 사용하여 데이터를 저장하고 검색하기 때문에 빠른 검색 속도를 제공할 수 있습니다.
- 데이터(Data)
해시 테이블에 저장되는 실제 데이터입니다. 데이터는 키-값 쌍의 형태로 저장될 수 있으며, 키를 통해 데이터에 접근하고 검색할 수 있습니다. 각 데이터는 해시 함수를 통해 생성된 해시 코드에 따라 적절한 버킷에 저장됩니다.
- 충돌 해결 메커니즘(Collision resolution mechanism)
해시 함수를 통해 생성된 해시 코드는 고유해야 하지만, 서로 다른 데이터가 동일한 해시 코드를 가질 수 있습니다. 이를 "충돌(collision)"이라고 합니다. 충돌이 발생할 경우에는 충돌 해결 메커니즘이 필요합니다. 일반적으로 충돌을 해결하기 위해 체이닝(Chaining) 또는 개방 주소법(Open addressing)과 같은 방법을 사용합니다.
- 개별 체이닝(Separate Chaining)
버킷의 개별 체이닝(Seperate Chaining)은 해시 테이블에서 충돌(Collision)이 발생했을 때, 충돌된 버킷에 연결 리스트나 링크드 리스트 등의 자료구조를 사용하여 충돌된 엔트리를 연결하는 방법입니다. 개별 체이닝은 충돌이 발생하면 데이터를 해당 버킷의 연결 리스트에 추가함으로써 충돌을 해결합니다.

해시 테이블의 기본 방식이기도 한 개별 체이닝(Separate Chaining)은 충돌 발생 시 그림과 같이 연결 리스트로 연결(link)하는 방식입니다. 충돌이 발생한 윤아와 서현은 윤아의 다음 아이템이 서현인 형태로 서로 연결 리스트로 연결되었습니다.
- 개별 체이닝(Separate Chaining)
- 로드 팩터(Load factor)
로드 팩터는 해시 테이블에 저장된 데이터의 양과 버킷의 수 사이의 관계를 나타냅니다. 로드 팩터는 해시 테이블의 성능에 영향을 미치는 중요한 요소로서, 적절한 로드 팩터를 유지하기 위해 필요에 따라 버킷의 크기를 동적으로 조절할 수 있습니다.
일반적으로 로드 팩터는 저장된 데이터의 수를 버킷의 수로 나눈 값으로 표현됩니다. 저장된 데이터의 수와 버킷이 1 : 1로 매칭되지 않는 이유는 개별 체이닝의 그림처럼 해시 값이 중복을 가질 수 있기 때문입니다.(이를 충돌[collision]이라고 합니다.) 로드 팩터는 해시 테이블의 성능과 공간 활용에 영향을 미치는 중요한 요소입니다. 로드 팩터가 높을수록 해시 테이블에 저장된 데이터의 양이 버킷 수에 비해 많다는 의미이고, 낮을수록 데이터의 양이 적다는 의미입니다.
➡️ 해시 테이블은 다음과 같은 단계로 동작합니다.
- 해시 함수 선택
데이터를 해시 테이블에 저장하기 전에 키를 해시 값으로 변환하는 해시 함수를 선택합니다. 해시 함수는 키의 일부분이나 전체를 입력으로 받아 해시 값으로 변환합니다.
- 해시 값에 따른 인덱스 계산
해시 함수를 사용하여 각 키에 대한 해시 값을 계산합니다. 이 해시 값은 일반적으로 정수로 표현되며, 해시 테이블의 인덱스로 사용됩니다. 해시 값의 범위는 해시 테이블의 크기에 따라 결정됩니다.
- 충돌 해결
서로 다른 키가 동일한 해시 값을 가질 수 있으므로, 이를 충돌(Collision)이라고 합니다. 충돌이 발생할 경우에는 충돌 해결 방법을 사용하여 충돌을 처리합니다. 대표적인 충돌 해결 방법으로는 개방 주소법(Open Addressing)과 연결 리스트(Chaining) 방식이 있습니다.
- 데이터 저장 및 검색
충돌이 발생하지 않는 경우에는 해시 값을 인덱스로 사용하여 데이터를 저장합니다. 이후에 데이터를 검색할 때에도 동일한 과정을 거쳐 해시 값을 계산하여 해당 인덱스로 접근하여 검색을 수행합니다.
🏷️이미지 출처 및 참고한 사이트
 https://www.geeksforgeeks.org/hashing-data-structure/
https://www.geeksforgeeks.org/hashing-data-structure/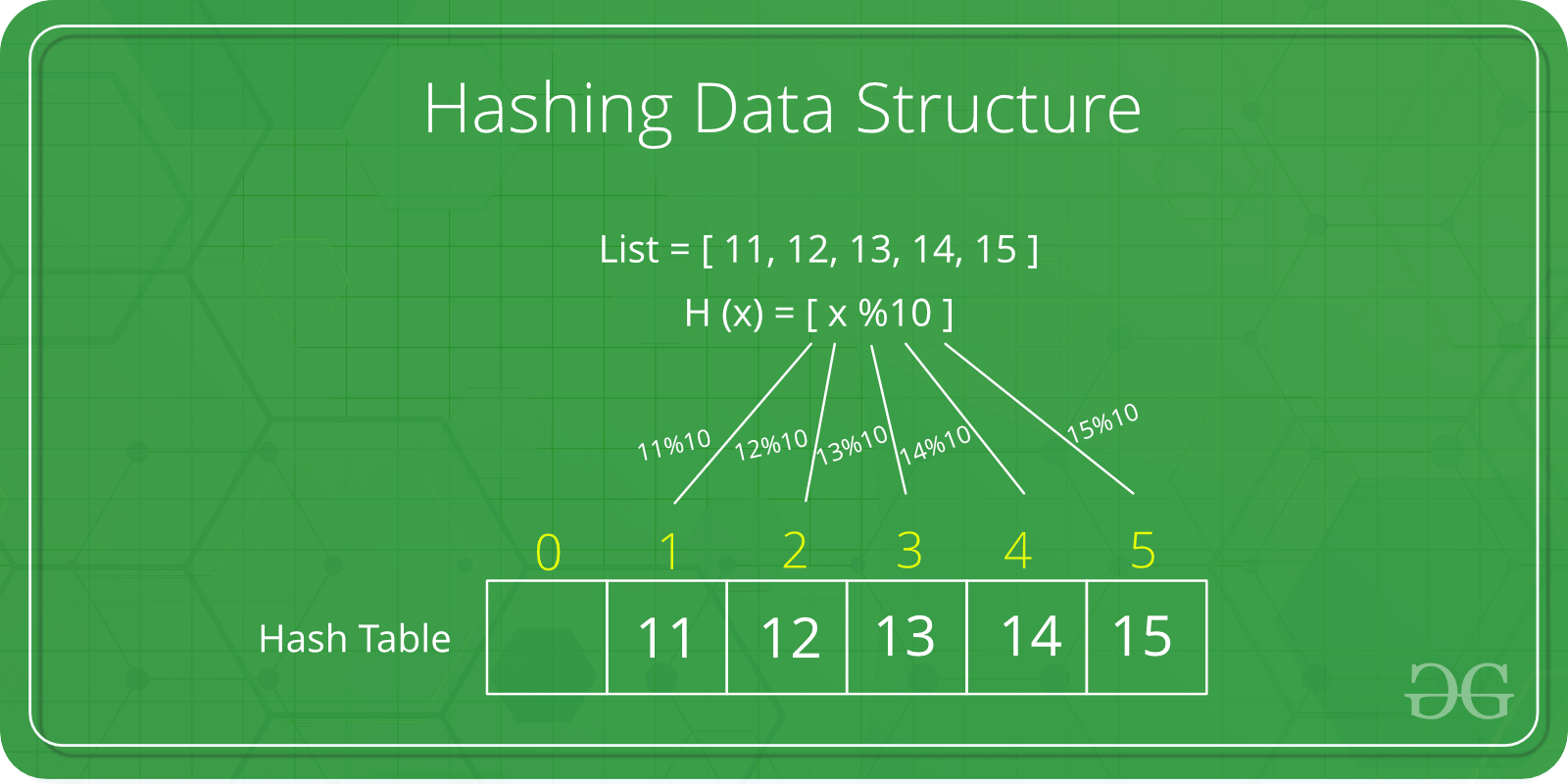
 https://ko.wikipedia.org/wiki/해시_테이블
https://ko.wikipedia.org/wiki/해시_테이블 https://www.geeksforgeeks.org/hashtable-in-java/
https://www.geeksforgeeks.org/hashtable-in-java/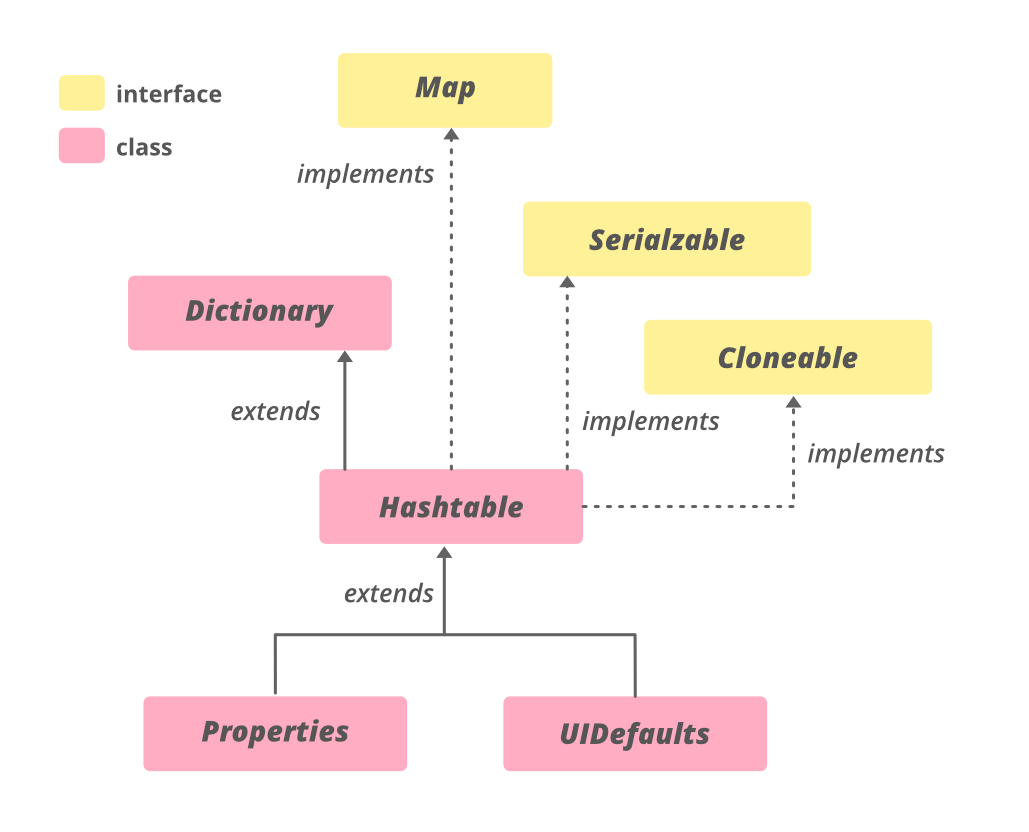
 https://sectigostore.com/blog/hash-function-in-cryptography-how-does-it-work/
https://sectigostore.com/blog/hash-function-in-cryptography-how-does-it-work/
Uploaded by N2T