✅ Spring Data JPA란?

Spring Data 프로젝트는 JPA, 몽고DB, REDIS, HADOOP, GEMFIRE 같은 다양한 데이터 저장소에 대한 접근을 추상화해서 개발자 편의를 제공하고 지루하게 반복하는 데이터 접근 코드를 줄여준다.
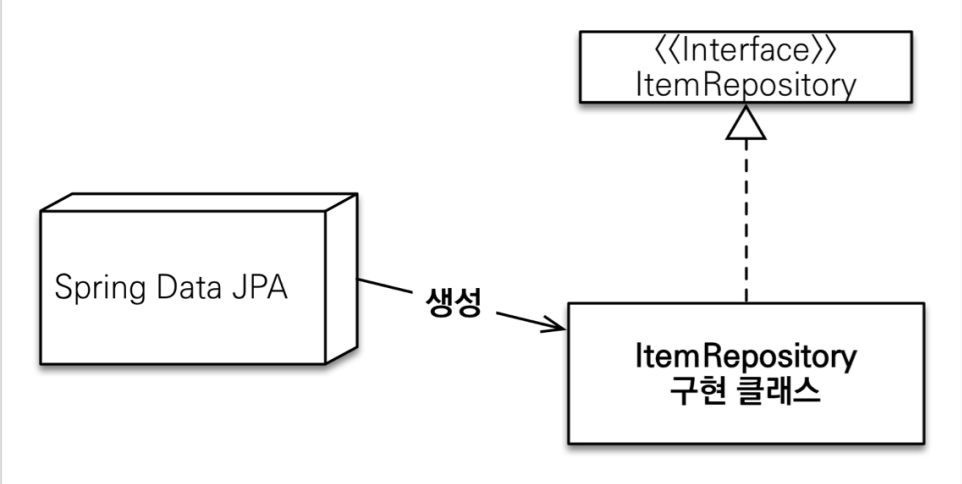
스프링 데이터 JPA는 스프링 프레임워크에서 JPA를 편리하게 사용할 수 있도록 지원한다. 따라서 데이터 접근 계층을 개발할 때 구현 클래스 없이 인터페이스만 작성해도 개발을 완료할 수 있다.

- 일반적인 CRUD 메소드는 JpaRepository 인터페이스가 공통으로 제공한다
save(S): 새로운 엔티티는 저장하고 이미 있는 엔티티는 수정한다.
delete(T): 엔티티 하나를 삭제한다. 내부에서EntityManager.remove()를 호출한다
findOne(ID): 엔티티 하나를 조회한다. 내부에서EntityManager.find()를 호출 한다.
getOne(ID): 엔티티를 프록시로 반환한다. 내부에서EntityManager.getReference()를 호출한다.
findAll(): 모든 엔티티를 조회한다. 정렬(sort)이나 페이지(pageable) 조건을 파라미터로 제공할 수 있다.
MemberRepository.findByUsername(..)처럼 개발자가 직접 작성한 메소드도 JPA가 메소드 이름(시그니쳐)을 분석해서 JPQL로 변환해서 실행하다. JPQL은 JPA 구현체(Hibernate)가 SQL로 변환해서 쿼리를 수행한다.
// 변환된 JPQL
SELECT m FROM Member m WHERE username = :username
✅ 쿼리 메소드(Query Method)
🔹메소드 이름으로 쿼리
public interface MemberRepository extends Repository<Member, Long> {
List<Member> findByEmailAndName (String email, String name);
}
인터페이스에 정의한 findByEmailAndName() 메소드를 실행하면 스프링 데이터 JPA는 메소드 이름을 분석해서 JPQL을 생성하고 실행한다. 실행된 JPQL은 다음과 같다.
SELECT m FROM Mernber m WHERE m.email = ?1 AND m.name = ?2
🔹JPA NamedQuery
@Entity
@NamedQuery{
name = "Member.findByUsername",
query = "select m from Member m where m.username = :username"
}
public class Member{
...
}
JPA는 선언한 “도메인 클래스 + .(점) + 메소드 이름” 으로 NamedQuery를 찾고, 없는 경우에는 메소드 이름으로 쿼리 생성 전략을 사용한다. (필요시 전략은 변경 가능하다)
🔹@Query
public interface MemberRepository extends JpaRepository<Member, Long> {
@Query("select m from Member m where m.username = ?1")
Member findByUserName(String username);
}
실행할 메소드에 정적 JPQL 쿼리를 직접 작성할 수 있다. 이름 없는 Named 쿼리라고도 한다. 위치 기반 파라미터가 1부터 시작한다. 이는 네이티브 쿼리와 차이가 있다.
- nativeQuery = true
@Query(value = "SELECT * FROM users WHERE username = ?0", nativeQuery = true) User findByUsername(@Param("username") String username);nativeQuery 속성을 통해서 네이티브 SQL을 직접 사용할 수 있다. 위의 코드는 JPQL이 아니고 DB에서 수행하는 SQL이다. 파라미터는 0부터 시작하기 때문에 유의해야 한다.
✅ 벌크 수정 쿼리 : @Modifying
// JPA 를 사용한 벌크성 수정 쿼리
int bulkPriceUp(String stockAmout){
String sqlString = "update Product p set p.price = p.price * 1.1 where p.stockAmout < :stockAmout";
int resultCount = em.createQuery(sqlString)
.setParameter("stockAmout", stockAmout)
.executeUpdate();
}
// 스프링 데이터 JPA 를 사용한 벌크성 수정 쿼리
@Modifying
@Query("update Product p set p.price = p.price * 1.1 where p.stockAmout < :stockAmout")
int bulkPriceUp(@Param("stockAmout") String stockAmout);
벌크성 쿼리를 실행하고 나서 영속성 컨텍스트를 초기화하고 싶으면 @Modifying(clearAutomatically = true) 속성을 사용하면 된다. 기본값은 false이다. 벌크성 쿼리는 쓰기 지연 저장소를 사용하지 않음으로 1차 캐시에는 여전히 벌크성 쿼리가 DB에 반영되기 전에 값이 남아있다. 따라서 영속성 컨텍스트를 초기화해서 새롭게 검색하는 엔티티들에 대해서 쿼리를 발생시켜 DB에서 새로운 값을 가져와야 동기화가 된다.
✅ 페이징과 정렬
스프링 데이터 JPA는 쿼리 메소드에 페이징과 정렬 기능을 사용할 수 있도록 2가지 특별한 파라미터를 제공한다.
- org.springframework.data.domain.Sort - 정렬 기능
- org.springframework.data.domain.Pageable - 페이징 기능(Sort 포함)
// count 쿼리 사용
Page<Member> findByName(String name, Pageable pageable);
// count 쿼리 사용 안 함
List<Member> findByName(String name, pageable pageable);
// 정렬
List<Member> findByName(String name, Sort sort);
반환 타입으로 Page를 사용하면 스프링 데이터 JPA는 페이징 기능을 제공하기 위해 검색된 전체 데이터 건수를 조회하는 count 쿼리를 추가로 호출한다.
🔹Spring MVC, 페이징과 정렬
스프링 데이터가 제공하는 페이징과 정렬 기능을 스프링 MVC에서 편리하게 사용할 수 있도록 HandlerMethodArgumentResolver를 제공한다.
- 페이징 기능 : PageableHandlerMethodArgumentResolver
- 정렬 기능 : SortHandlerMethodArgumentResolver
🤖 예시 코드
@RequestMapping(value = "/members", method = RequestMethod.GET)
public String list(Pageable pageable, Model model) {
Page<Member> page = memberService.findMembers(pageable);
model.addAttribute("members", page.getContent());
return "members/memberList";
}
- 접두사
- 사용해야 할 페이징 정보가 둘 이상이면 접두사를 사용해서 구분할 수 있다. 접두사는 스프링 프레임워크가 제공하는
@Qualifier어노테이션을 사용한다. 그리고 "{접두사명}_"로 구분한다.public String list( @Qualifier ("member") Pageable memberPageable, @Qualifier ("order") Pageable orderPageable, ... // ex) members?member_jpage=0&order_page=1URI 파라미터로 넘어온 값을 바인딩해서 사용한다.
- 사용해야 할 페이징 정보가 둘 이상이면 접두사를 사용해서 구분할 수 있다. 접두사는 스프링 프레임워크가 제공하는
🏷️이미지 출처 및 참고한 사이트


Uploaded by N2T